How to
Build Neural Text Search Engine in 10 minutes
Improve search relevance by going beyond the conventional keyword-based search!

RE: Neural Search
Neural search leverages deep neural networks to intelligently search through all sorts of data, including images, videos, and PDFs. This innovative approach provides a much more comprehensive and contextual search than traditional text-based search engines.

Tutorial → Setting up the Neural Search Engine
Let’s dive into a quick tutorial to set up your neural search engine for textual data using Jina’s DocArray in Python. This blog does not serve as an introduction to neural search. Check out this article for background.
The idea behind this tutorial is to build a neural search on textual data. It will work by taking in the query sentence as input matching it with sentences in our dataset and returning the matched sentences as the output.
👩💻 Technical Stack → Jina’s DocArray, Python 3.7+
📚 Database Used → Pride & Prejudice e-book
Installing Dependencies
To get started, you need to install DocArray from PyPI. To do that, you can use the following command:
- Via Pip:
pip install docarray - Via conda:
conda install -c conda-forge docarray
Code Walkthrough
First, we need to load the dataset from a URL, convert it into text, and put it into a Document.
Next, since our dataset is an amalgamation of long sentences, we need to break it into smaller chunks that can be converted into a DocumentArray. We split the sentences using the ‘\n’ symbol i.e. whenever a new line is encountered. We store that sentence as a Document in the DocumentArray.
Next comes the vectorization of features (i.e. we need to convert our features into indices in a vector/matrix). The features in this example become the embeddings of each Document in our DocumentArray.
There are many ways to do this but a faster and space-efficient way is to use feature hashing. It works by taking the features and applying a hash function that can hash the values and return them as indices. But, DocArray saves us from the computation, and using feature hashing is as easy as a single line of code.
To get the Output 👉
We take the query sentence and convert it into a Document, vectorize it, and then match it with the vectors of the Documents in the DocumentArray.
Let’s take the query sentence "she entered the room" from Pride and Prejudice and see what response we get.
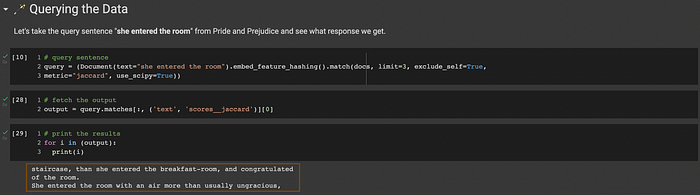
🥷 Neural Text Search in Action
We have created a colab notebook with a code walkthrough where you can build and run the text search engine in the cloud using the Pride and Prejudice dataset.
Follow along with the colab notebook 👉
References
If you would like to learn more or want me to write more on this subject, feel free to reach out.

If you liked this post or found it helpful, please take a minute to press the clap button, it increases the post's visibility for other medium users.
